
Uniform Resource Locator (URL) identifiers are unique addresses on the Internet. A URL is a specific type of Uniform Resource Identifier (URI). It is used to reference Web pages and identify and transfer documents on the Web by providing an abstract identification of the resource’s location. This is why it is also known as a web address.
Structure of a URL
A URL is what you type in the browser address bar to request a specific resource. You can see the parts it consists of in the graphic below.
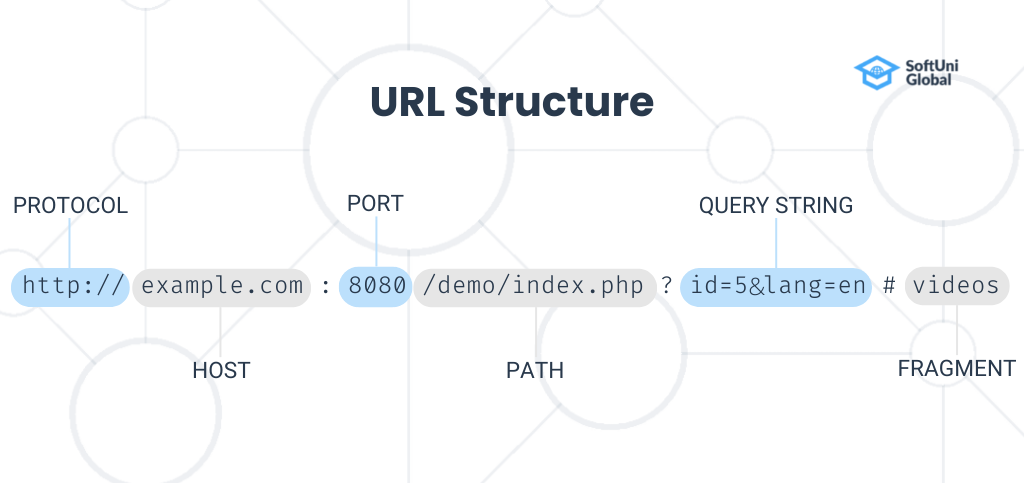
The first part of a URL specifies the protocol that the browser must follow to talk to the server. The protocol is used to access remote resources, such as files, documents, and streaming media. It can be http, https, ftp, sftp, or other. Usually, for webpages is used HTTP and HTTPS.
After the protocol is the host. The host is usually a domain name, but an IP address can also be used. It indicates the web server that you request resources from.
The third part of the URL is the port This is an integer in the range of [0…65535] that comes from the underlying TCP protocol, which operates with port numbers. The port is a virtual point through which network communication happens. It can be omitted if the server uses default ports of the HTTP protocol which are 80 for HTTP and 443 for HTTPS.
The host and the port define the endpoint for establishing the connection with the server.
The next part of the URL is the path. It specifies the location of the web page, file, or other resources to which the user wishes to gain access. If you want to request a file from the Web server, this will be the full path to the file, relative to the server root folder.
After the path follows the query string, which is optional. It is separated from the path by a question mark symbol. It holds parameters passed in the URL which are separated from each other by an ampersand symbol.
The fragment is the last optional part of the URL. It follows after the “hash” symbol. For example, the URL can end with “#slides“, which instructs the Web browser to scroll to the section “slides” in the loaded HTML document. The fragment is never sent to the server with the request.
A rarely used URL format can also include authentication data, sent through the “Authorization” HTTP header. For example http://username:[email protected]/
Query String
The query string is an optional part of the URL. It contains data that is not part of the path structure.
For example, let’s look at this URL:
http://example.com/path/to/page?name=tom&color=purple
The query string is ?name=tom&color=purple
The query string is commonly used in searches and dynamic pages. It consists of name=value pairs separated by an ampersand delimiter. Names and values that hold special characters are URL-encoded.
For example https://nakov.com/?s=Svetlin%20Nakov
URL Encoding
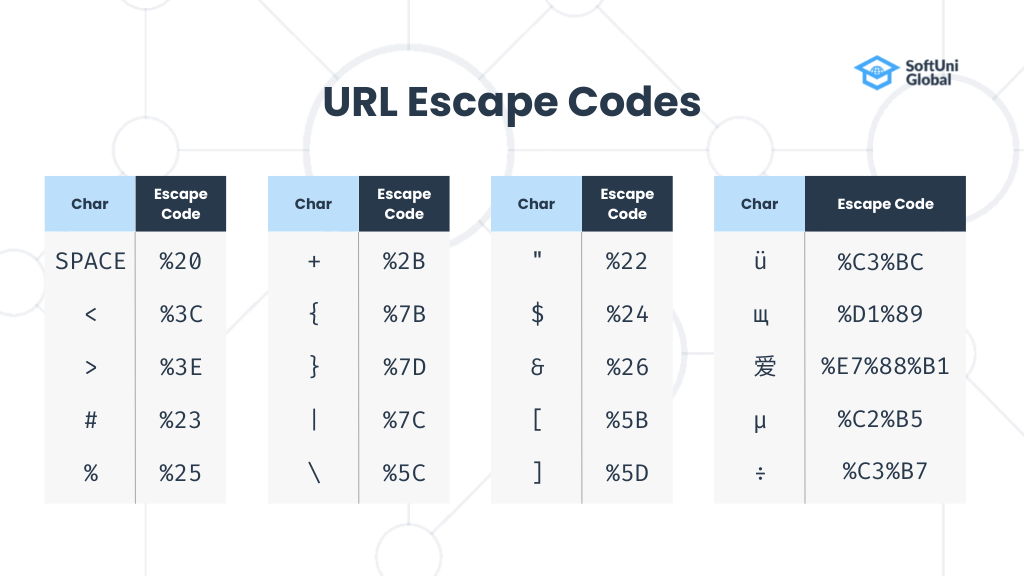
Sometimes the query string parameters need to hold special characters like the “=” symbol or the “?” symbol. To maintain this, the query string needs character escaping, which means that some special characters are replaced by sequences of other characters. This is called “URL encoding“. URLs are encoded according to RFC 1738 standard, which describes the URLs). Normal URL characters (such as digits and Latin letters) have no special meaning in the URLs and are not encoded. Reserved URL characters have a special meaning and are encoded in order to be part of the URL without breaking it. This is done with the so-called “percent encoding“, which uses the “%” symbol plus the hex code of the character in its UTF-8 representation. You can see some examples of URL escape codes in the graphic above.
Lesson Topics
- What is URL;
- Structure of a URL;
- Query Strings;
- URL Encoding.


