
The Hypertext Transfer Protocol (HTTP) is the standard protocol used to transmit data across the web. It is originally created to transfer HTML, CSS, images and other Web resources within the global distributed information system called the “World Wide Web” (or just Web). Later, HTTP is extended to a general-purpose client-server protocol for the Internet and is widely used for transferring almost anything: text, images, documents, audio and video and more.
What is a protocol?
A communication protocol is a set of rules, which define how two or more parties are talking to each other. It is like a common language used for communication between machines.
HTTP is a text-based client-server protocol. Client-server defines the parties communicating with each other: the client – software that reads and visualizes the data from the server, and the server – software that stores the data and provides it upon request in the form of an HTML document.
The HTTP protocol uses the request-response model. It means that a site or a resource will not be open unless the client has asked for it. Therefore, the client has to send a request for a given data and the server will return a response containing the required data.
The HTTP protocol relies on unique resource locators (URLs), like “https, column, slash, slash, softuni dot org”. When a resource is downloaded from the Web server, it comes with metadata (such as content type and encoding), which helps in visualizing the resource correctly.
Moreover, the HTTP protocol is stateless. Each HTTP request is independent from the others. Stateful HTTP conversations can be implemented by extra effort, using cookies, custom header fields, Web storage or other techniques.
HTTP Request Structure
Let’s see the structure of an actual request.
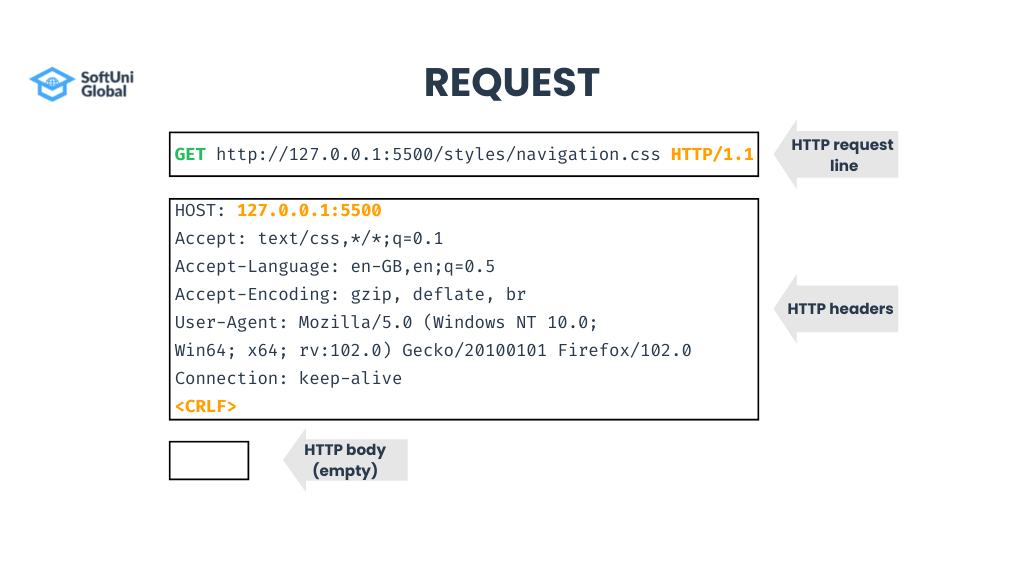
HTTP requests have a line, headers, a new line (CR + LF) after that, and a body at the end.
The HTTP request line is the command you send to the server to indicate what resource you want to get or process. It consists of:
- Request method (in our example “GET”);
- Request-URL (this is the resource path);
- HTTP version string.
Web browsers use URLs, but HTTP uses URIs to address the resources.
- URL stands for “uniform resource locator” and it describes a full unique address for a resource on the Internet, which consists of protocol + host + resource path, like in the example above
- URI stands for “uniform resource identifier” and it holds a full or relative unique path to a resource, for example “/about“.
When you request a resource over HTTP, you specify the relative URI of the resource in the request line and you specify the host name in the request headers. Both relative URI and host name come from the URL you want to access.
After the request line, the HTTP request headers are given. Headers specify specific parameters about the requested resource:
- “Host” is an important header, holding the requested resource. If we have several Web sites on the same Web server (for example softuni.org and learn.softuni.org), this “Host” header will tell the server which website to access.
- The other headers specify settings like what kind of content the client can accept and understands (for example only HTML or any content), what is the preferred language the client wants to use, what kind of compression the client understands (for example gzip and deflate), what are the client Web browser’s brand and version (encoded as the so-called “user agent” identifier) and other parameters.
- The headers section in the HTTP request ends by an empty line (CR + LF twice).
After the request headers, comes the request body.
- It can hold anything, for example, URL-encoded data or JSON objects or binary data.
- In the given example the body is empty, which is typical for HTTP GET requests.
HTTP Request Methods
The HTTP request method defines what action will be performed on the identified resource. The most commonly used HTTP methods are GET, POST, PUT, DELETE and PATCH which correspond to read, create, update and delete (or CRUD) operations, respectively.
Idempotency and safety are properties of HTTP methods.
Safe methods can only be used for read-only operations since they do not alter the server state. Using GET or HEAD on a resource URL, for example, should never change the resource. Safe methods are considered GET, HEAD, TRACE and OPTIONS.
Idempotent methods can send multiple identical requests to the server and the outcome will always be the same and it does not matter how many times the requests will be sent. This does not mean, however, that the server has to respond in the same way to each request. For example, if we want to delete a resource we send a DELETE request. The first time the server returns a response that the file has been deleted. If you try to send the same request again the server will respond that the file has already been deleted. Here we have two different responses but the second request did not alter the server state. In this case, the DELETE operation is idempotent.
The following HTTP methods are idempotent: GET, HEAD, OPTIONS, TRACE, PUT and DELETE. All safe HTTP methods are idempotent. PUT and DELETE are idempotent but not safe.
You can see all methods and their function in the graphic below.

The main HTTP methods corresponding to the CRUD operations are POST, GET, PUT/PATCH and DELETE.
- The GET method retrieves a specified resource (a list or a single resource). If there are no errors the method returns a representation of the resource in XML or JSON. GET is used to download a Web page, CSS file, script, document or other resources from a Web site. For example, a Web page’s content (fonts, images, etc.) is loaded using HTTP GET requests. This does not modify the state at the server-side, it only ‘reads’ it.
- The POST method modifies the state of the server since it creates new resources. For example, when you login into a website, the login sends your credentials to the server using a POST request.
- DELETE is used to delete (or remove) an existing resource. An example of an HTTP DELETE request is for deleting an item from the shopping cart in an e-commerce Web application.
- The PATCH method updates an existing resource partially. It is used to modify a field of a given object. An example is an HTTP PATCH request for updating the quantity of an order item in the shopping cart in an e-commerce Web application.
- The HTTP HEAD method retrieves the resource’s headers, without the resource itself. HEAD is used rarely, for example, to check for modifications on the server-side.
HTTP Response Structure
After receiving and interpreting a request message, the server sends an HTTP response message. You can see an example below.

The response message gives information on whether our request has been successfully executed or has failed. It consists of a status line, response headers and a response body.
The HTTP response status line starts with the protocol version, followed by the response status code, followed by a human-readable text explanation of the status code.
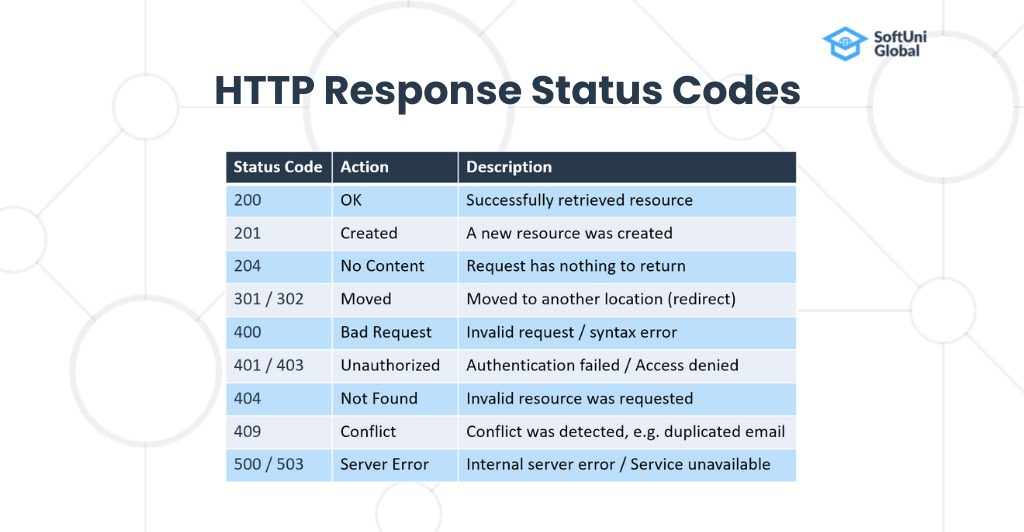
The status code tells the client whether the requested operation was successful or not. It is a three-digit integer whose first digit defines the response class.
Status codes are:
- Informational responses (100–199)
- Successful responses (200–299)
- Redirection messages (300–399)
- Client error responses (400–499)
- Server error responses (500–599)
You can check the graphic below to see the most common status codes.
After the HTTP status line come the HTTP response headers that provide metadata for the returned resource (or the returned error), such as content-encoding, content size in bytes, content last-modify date and many others.
After the response headers and the empty line separator, the HTTP response body comes. This is the requested resource that can be text, binary data or it can be empty. In the example we used above, the Web server returns a CSS script for styling a navigation bar.
Content-Type and Disposition Headers
HTTP headers play an important role in modern Web development.
The “Content-Type” and the “Content-Disposition” headers specify how to process the data in the HTTP request or in the HTTP response body. These headers can be used both in the HTTP requests and in the HTTP responses.
In the HTTP requests, the “Content-Type” header specifies what kind of data the client sends to the server, for example, a JSON document or URL-encoded form data or a plain-text document or a JPEG image. In the HTTP responses, the “Content-Type” header specifies what kind of data the server returns to the client, for example an HTML document or a JPEG image.
For example, the header “Content-Type: application/json” specifies a JSON-encoded data (a JSON object). By default, the UTF-8 encoding is used.
The “Content-Type: text/html; charset=utf-8” specifies an HTML document with UTF-8 encoding. Note that the encoding (or the charset) specified in the HTTP headers has a higher priority than the encoding specified in the header of the HTML document (using the “meta charset” HTML tag).
HTTP Dev Tools

There are browser built-in tools and client tools that help developers monitor the request-response traffic. An example of a client tool is the Postman HTTP client. Web developers use it for composing and sending HTTP requests and analyzing the HTTP response from the server, testing, debugging server APIs, researching how to use certain service APIs and for resolving technical issues during the software development. If you are interested in other HTTP client tools, you can try out Insomnia Core REST Client and Hoppscotch.
Lesson Topics
- What is the HTTP Protocol
- HTTP Request Structure
- HTTP Request Methods
- HTTP Response Status Codes
- Content-Type and Disposition Headers


